Cluster topology - Cassandra rack aware deployments
CassKop rack awareness feature helps to spread the Cassandra nodes replicas among different racks in the kubernetes infrastructure. Enabling rack awareness helps to improve availability of Cassandra nodes and the data they are hosting, through correct use of Cassandra's replication factor.
note
Rack might represent an availability zone, data center or an actual physical rack in your data center.
Quick overview#
CassKop awareness can be configured in the CassandraCluster.spec.topology section.
If the topology section is missing then CassKop will create a default Cassandra DC dc1 and a default Rack
rack1.
In this case, CassKop will not use specific kubernetes nodes labels for placement and in consequence the cluster is
not rack aware.
In the topology section we can declare all the Cassandra Datacenters (DCs) and Racks, and for each of them we provide
labels which will need to match the labels assigned to the Kubernetes cluster nodes.
Each of our rack targets Kubernetes nodes having the combination of labels defined in the dc section and in the rack
section. The labels are used in Kubernetes when scheduling the Cassandra pods to kubernetes nodes.
This has the effect of spreading the Cassandra nodes across physical zones.
important
CassKop doesn't rely on specific labels and will adapt to any topology you may define in your datacenter or cloud provider.
Kubernetes nodes labels#
Cassandra will run on Kubernetes nodes, which may already have some labels representing their geographic topology.
Example :
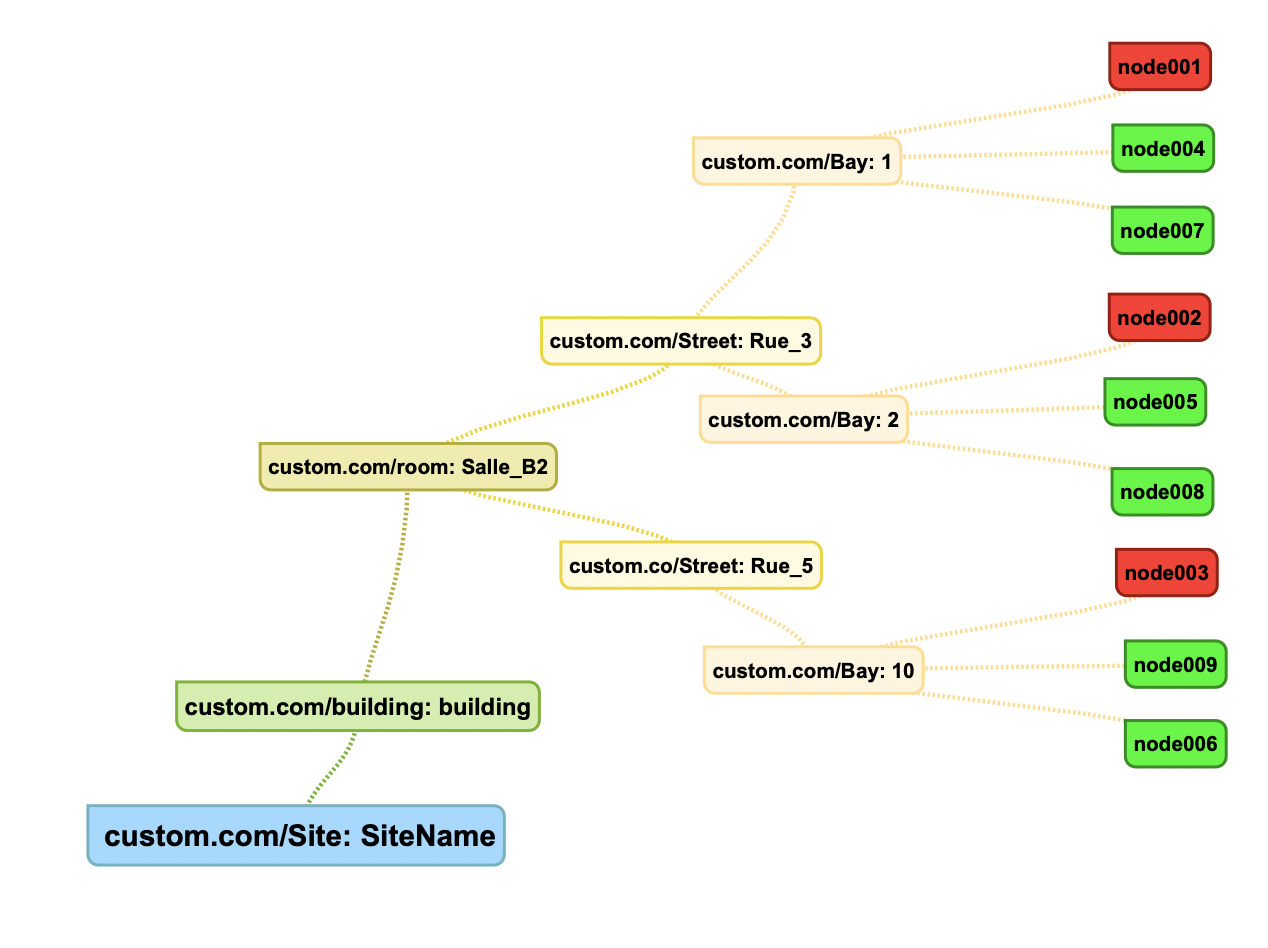
Example of labels for node001 in our dc:
In the cloud the labels used for topology may better look like :
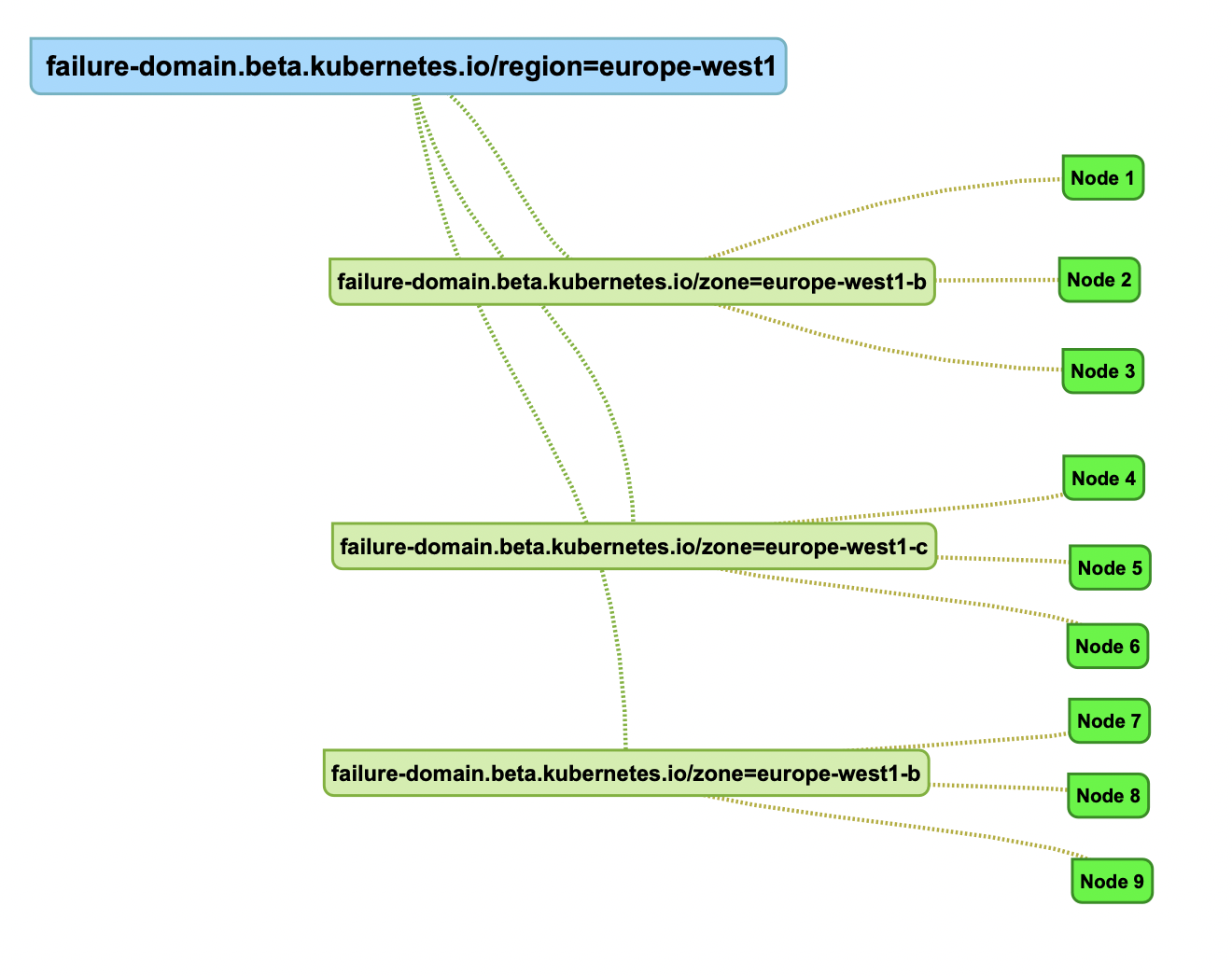
The idea is to use the Kubernetes nodes labels which refer to their physical position in the datacenters to allow or not Cassandra Pods placement.
Because CassKop manages its Cassandra node pods through statefulsets, each pod will inherit the placement configuration of its parent statefulset. In order to place pods on different racks, we need to associate a new statefulset with specialized node placement constraints for each Cassandra rack we define.
Because the AZ feature was not yet available for statefulsets when we began to develop CassKop, we chose to implement 1 statefulset for 1 Cassandra Rack. Hopefully, we will be able to benefit of improvements about the topology-aware dynamic provisioning feature proposed in future version of K8S (more information here : https://kubernetes.io/blog/2018/10/11/topology-aware-volume-provisioning-in-kubernetes/
See an example of configuration with topology : cassandracluster-demo-gke.yaml
Configuring pod scheduling#
When two applications are scheduled to the same Kubernetes node, both applications might use the same resources like disk I/O and impact performances. It may be recommended to schedule Cassandra nodes in a way that avoids sharing nodes with other critical workloads. Using the right nodes or dedicated a set of nodes only for cassandra are the best ways to avoid such problems.
Placement of Pods in a Statefulsets are done using NodeAffinity and PodAntiAffinity :
- nodeAffinity will be used to select specific nodes which have specific targeted labels.
- podAntiAffinity can be used to ensure that critical applications are never scheduled on the same node.
Cassandra node placement in the Kubernetes cluster#
Node affinity#
To target a Specific Kubernetes group of Nodes CassKop needs to define a specific nodeAffinity
section in the targeted dc-rack statefulset to match specific kubernetes nodes labels.
Example. If we want to deploy our statefulset only on nodes which have these labels :
CassKop need to add this section in the Statefulset definition :
All Pods that will be created from this statefulset will target only nodes which have these 4 labels. If there is no kubernetes nodes available with these labels, then the statefulset will remain stuck in a pending state, until we correct either labels on nodes, or deployment constraints definition of the statefulset.
We can also use specific labels to dedicate some kubernetes nodes to some type of work, for instance dedicated some nodes for Cassandra.
You can define custom labels on kubernetes nodes :
This is done automatically by combining the labels you specify in the Cassandra CRD definition in the
Topologysection.
Pod anti affinity#
If we lose a Kubernetes node, then we may want to limit the impact to loosing only one Cassandra node. Otherwise, depending on the replication factor, we may have a data loss.
In our CassandraCluster, the statefulset will target a pool of Kubernetes nodes using it's NodeSelector we just saw above. All these Pods will inherit the specific labels from the Statefulset.
To implement the limitation "one Cassandra Pod per Kubernetes node", we use the pod definition section
podAntiAffinity. This tells kubernetes that it can't deploy to a Kubernetes node, if a pod having the same labels
already exist.
This Tells that we Require not deploy to a node if a pod already exists with these existing labels.
This is configured by default by CassKop
Using dedicated nodes#
Cluster administrators can mark selected kubernetes nodes as tainted. Nodes with taints are excluded from regular scheduling and normal pods will not be scheduled to run on them. Only services which can tolerate the taint set on the node can be scheduled on it. The only other services running on such nodes will be kubernetes system services such as log collectors or software defined networks
Taints can be used to create dedicated nodes. Running Cassandra on dedicated nodes can have many advantages. There will be no other applications running on the same nodes which could cause disturbance or consume the resources needed for Cassandra. That can lead to improved performance and stability.
Example of tainting a node :
Additionally, add a label to the selected nodes as well
Pod tolerations like pod annotations can be added to created pods by using the pod entry in the spec section of the cassandracluster object as below :
important
toleration must be used with node affinity on the same labels
Configuring hard antiAffinity in Cassandra cluster#
In development environment, we may have other concern than in production and we may allow our cluster to deploy several nodes on the same kubernetes nodes.
The boolean hardAntiAffinity parameter in CassandraCluster.spec will define if we want the constraint to be
Required or Preferred
If hardAntiAffinity=false then the podAntiAffinity will be preferred instead of required and then kubernetes
will try to not put the cassandra node on the kubernetes node BUT it will allow to do it if it has no other choices.
Cassandra notion of dc and racks#
As we previously see, the Cassandra rack awareness is defined using several Cassandra datacenters dcs and racks.
The CassandraCluster.spec.topology section allows us to define the virtual notion of DC & Rack.
For each we will define Kubernetes labels that will be used for pod placement.
The name and numbers of labels used to define a DC & rack is not defined in advance and will be defined in each CassandraCluster manifests, depending on labels presents on Kubernetes Nodes and the required topology
Configure the CassandraCluster CRD for dc & rack#
If the section topology is missing:
- then CassKop will deploy without label constraints to any available kubernetes nodes in the cluster
- there will be only one DC defined named by default dc1
- there will be only one Rack defined named by default rack1
If the topology section is defined, this will enable to create specific Cassandra dcs and racks: this creates a specific statefulset for each rack and deploys on Kubernetes nodes matching the desired Node Labels (the concatenation of DC labels + Rack labels for each statefulset)
Example of topology section:
- This will create 2 Cassandra DC (
dc1&dc2)- For DC
dc1it will create 2 Racks :rack1andrack2- In each of these Racks there will be 3 Cassandra nodes
- The
dc1will have 6 nodes
- For DC
dc2it will create 1 Rack :rack1- the
dc2overwrite the global parameternodesPerRacks=3with a value of4. - The
dc2will have 4 nodes
- the
- For DC
important
We want to have the same numbers of Cassandra nodes in each Rack for a dedicated Datacenter. We can still have different values for different datacenters.
The NodeSelectors labels for each Rack will be the aggregation of labels of the DC and the labels for the Racks :
For instance with this example, NodeSelectors labels for dc1 / rack2 will be :
The
dc/racktopology definition is generic and does not rely on particular labels. It uses the ones corresponding to your needs.
note
The names for the dc and rack must be lowercase and respect Kubernetes DNS naming which follow RFC 1123
definition which can be expressed with this regular expression :
[a-z0-9]([-a-z0-9]*[a-z0-9])?
How CassKop configures dc and rack in Cassandra#
CassKop will add 2 specific labels on each created Pod to tell them in witch Cassandra DC and Rack they belong :
Example :
Using the Kubernetes DownwardAPI, CassKop will inject into the Cassandra Image 2 environment variables, from these 2 labels. Excerpt from the Statefulset template :
In order to allow configuring Cassandra with the DC and Rack information, we use a specific Cassandra
Image, which has a startup script that will retrieve
these environment variables, and configure the Cassandra cassandra-rackdc.properties file with the values for dc and
rack.
The Cassandra Image makes use of the GossipingPropertyFileSnitch Cassandra Snitch, so that both Kubernetes and Cassandra are aware of the chosen topology.